Developers
What is Prometheus? | Storm Internet
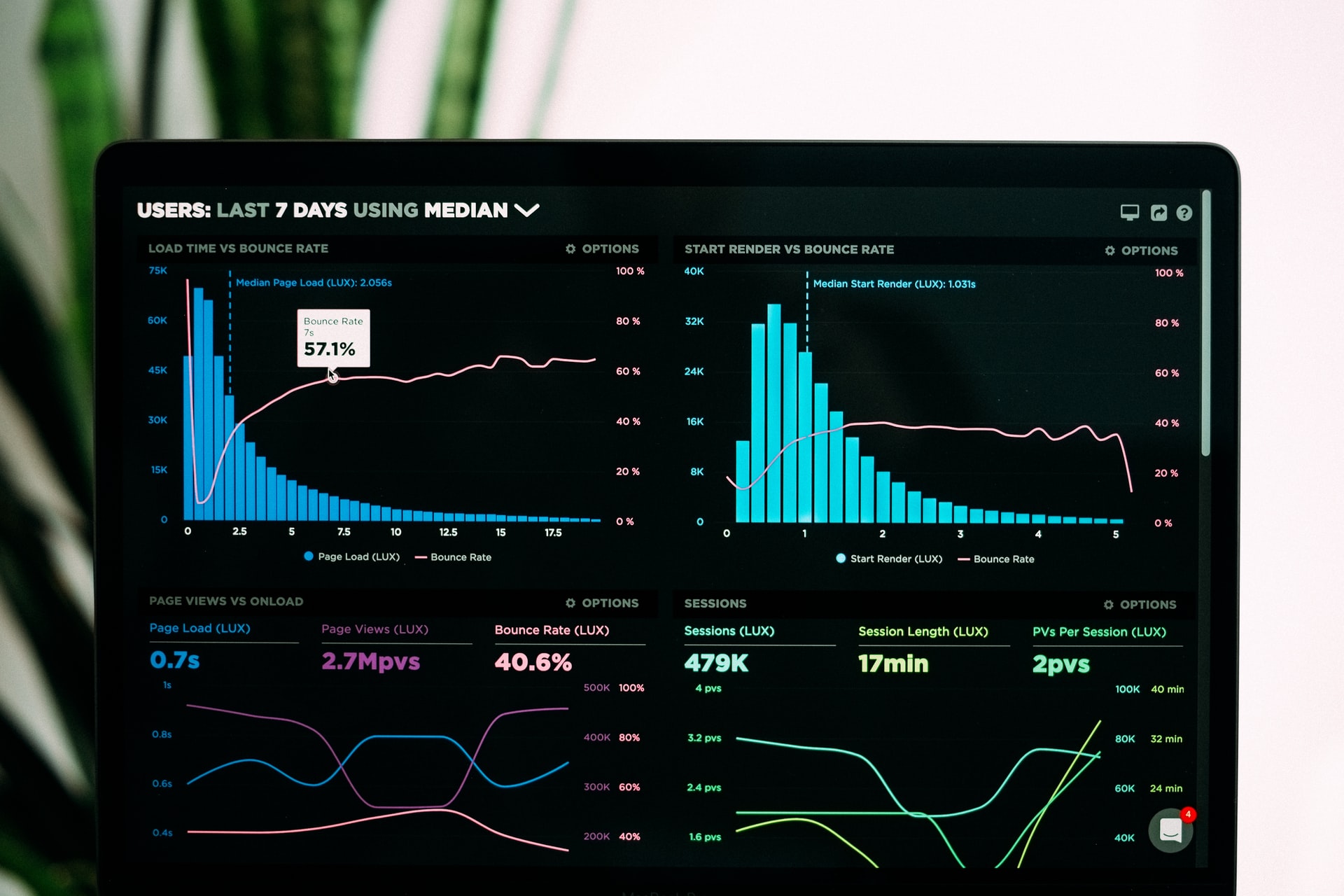
Prometheus Performance Monitor
Prometheus is an open source performance monitoring tool first developed at SoundCloud. (SoundCloud is not the only media company to have one of those. Netflix built Vector which you can get here. But Prometheus is better since it is far more sophisticated and is a truly open source project and has many more users.) As to what other product is similar to Prometheus, Prometheus has documented their own side-by-side comparison with Graphite.
Prometheus is designed to gather metrics and store them as a time series. That is a perfect fit for performance monitoring, where you monitor variables over time, like cpu usage, etc.
What Prometheus does is similar to what ELK (ElasticSearch, Kibana, and Logstash) popular log monitor tools do which is gather up logs and send them to a central repository. But Prometheus is geared towards performance monitoring, so it has items like alerting and thresholds.
Download it from Docker and Go!
Like most complex tools, you can get Prometheus up and running quickly to test it out by running it as a Docker container, like this:
docker run -d -p 9090:9090 prom/prometheus
That’s it. Now you have a running Prometheus system and can open the console.
Architecture Diagram
As with any tool, you can use the easiest functions first and then dive into something more complex if you need something deeper than that.
An easy way to start is to use the Prometheus auto-discovery feature called Node Explorer. You install that on target machines and it starts sending metrics to Prometheus about cpu, memory, etc. Of course you would not want to install that as a Docker image, as it would only report on the Docker image and not the machine itself.
The Goal of Performance Monitoring and Prometheus Metrics
The problem with most monitoring systems is what is called the signal-to-noise-ratio problem. That means the system spits out so many false alerts that the technicians monitoring those tend to ignore them. Alerts should be set only for events that are statistically significant. That would be the application of analytics to monitoring. Unfortunately it does not look like many or any tools actually work that way. You would have to write your programs to do that, which you can certainly do, since Prometheus has an API.
Instead with Prometheus you define thresholds to create alerts, the same as you would with other monitoring systems. Their syntax is:
ALERT
IF
[ FOR ]
[ LABELS ]
[ ANNOTATIONS ]
As Prometheus itself writes, “Prometheus’s alerting rules are good at figuring what is broken right now, but they are not a fully-fledged notification solution.” To do that you need to track metrics over time and not just at an instance in time. But Prometheus does that through the data structures we discuss next.
Counter, Gauge, Histogram, and Summary
Prometheus gathers metrics in a way that other systems like ELK graph them as a visualization. The Prometheus abstraction is very useful as you can write alerts and Python code snippets etc. to report on buckets of data that have already been summarized for you.
The counter is a count of a metric over time, like number of errors. A gauge is a single stat, like temperature, right now. The histogram is a counter divided into time slices, just like a histogram graph. The summary provides several items including a counter of a metric over a configurable sliding window.
Grouping, Inhibition, and Silences
Prometheus does a good job at tackling the noise-to-signal-ratio problem with the Alert Manager tools of Grouping, Inhibition, and Silences. Basically grouping causes alerts that are similar in nature to be sent all together. That is better that firing off multiple emails for a bunch of related events. Inhibition causes Prometheus to momentarily stop alerting in one area when another area is having trouble. That is logical as you would want to, for example, not report on machine metrics when an entire network segment is down. And silences lets you cut off particular alerts for a specific period of time.
Querying
Prometheus supports its own query language. That is much different the ELK approach which is to use what is called Lucene Query, which is basically simpler and has become something of a standard. But as with any language, Prometheus queries can be more powerful as they support data structures and functions.
Much of that is not going to make any sense to you unless you know something about programming, but every system administrator should know or learn at least one language, particularly Python.
But do not fear as to use Prometheus you do not need to master the complex functions right away. Instead, for example, if you want a list of all http requests you just type:
http_requests_total
And then here is the request for second for the last 5 minutes:
rate(http_requests_total[5m])
This name http_requests_total is a Prometheus metric name. So it is not, for example, a metric straight from the Apache web server. Instead it has been defined in Prometheus. It is a combination of a label (for example http POST) and a handler (/some/url). So these are objects you have to define. Many are already defined for you.
In Summary
Basically, you could conclude that in order to use Prometheus you are going to have to be comfortable with abstractions and it would be helpful if you know how to write some code. But the learning curve does not appear steep. And it should provide a more powerful performance monitoring tool as Prometheus data structures and query functions lets you tailor monitoring to your specific situation and solves the signal-to-noise problem that plagues so many other performance monitoring systems. It does not have any advanced analytics on board, but if you understand statistics and machine learning you could use its APIs to implement that kind of monitoring too.
More related news

Cloud Hosting
Cloud Server vs VPS: What’s the Difference and Which Is Better for Your Business?
If you’re running a SaaS platform, digital agency, ecommerce store, education portal,...

Developers
Low-code + custom: when to use low-code tools in your SaaS stack (and when not to)
Low-code has become a practical part of many SaaS stacks – because...

SaaS
Managing Unplanned Growth: Autoscaling & Cost Controls for Burst Traffic
When growth arrives unannounced – viral link, investor announcement, seasonal rush –...
Speak with a Storm Expert
Please leave us your details and we'll be in touch shortly
A Trusted Partner
